
How to Train a Deep Learning System for Machine Vision
How to Train a Deep Learning System for Machine Vision
As outlined in our last blog post, there are a wide range of attractive benefits to be gained from implementing a deep learning machine vision system in industrial settings. We covered the definition of deep learning, machine learning and AI, and touched on data sets and the preparation required in training a deep learning system for machine vision projects.
In this blog post we will be fleshing out this topic and outlining the stages you will need to carry out in order to train a deep learning system for machine vision.
Training a Deep Learning System with Data Sets
Data sets for deep learning solutions are as important as mains electricity. It is the ‘education’ that a model needs in order to start functioning as intended. For a definition and introduction to data sets, check out our last blog post.
Without a data set to be processed by your model, it will not know how to make distinctions between variables in images and will ultimately fail at the intended use.
Data Subsets for Machine Vision
It is ideal to use so many images for a data set because they will need to be allocated into at least two (preferably three) subsets prior to training. The first subset (the ‘training’ set) is used to do the actual training of the model, which involves adjustments to mathematical weights.
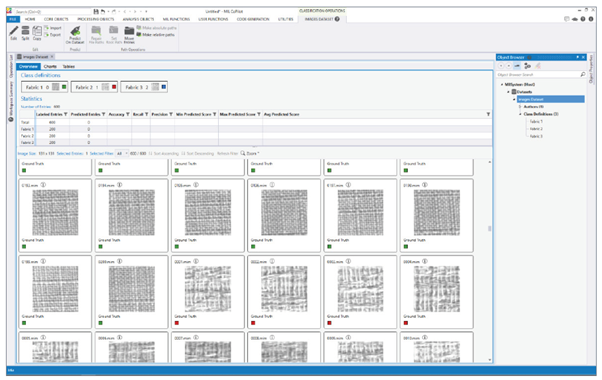
Organising and labelling the training set using Matrox Imaging Library (MIL) CoPilot.
The ‘development’ (or ‘validation’) set is the second subset you will need. This subset is used to supervise the training process by tracking the difference between the real and expected classification outcomes.
The third subset, the ‘test’ set, is optional, and is used at the very end of the data set training process to independently assess the performance of the trained model; if the test set is not used, the development set would also take on this performance assessment role.
Building a good data set
Your data set needs to closely match the images you expect to obtain in your actual project.
The more variables you can think of, the better. The greater number of unique items in your data set, the better. If you can maintain a consistent environment (such as illumination) between your data set and your project in practice, the more accurate your AI’s inferences and decision-making abilities will be.
What kind of data do I need?
In the context of deep learning for machine vision, your data set will consist of images of objects that differ based on the possible variations of those objects. As we have outlined so far, deep learning vision systems are best at classification, recognition, reading, and detecting.
Think about how you want to start automating your processes – try starting small, for example with basic detection of an object’s presence, and work your way towards more nuanced inferences, such as classification and reading.
Optical character recognition (OCR) is a task that deep learning excels at. For this, your data set would consist of many variations of all possible characters that may come up in practical imaging.

MNIST is a very popular open-source deep learning dataset comprising 70,000 examples of handwritten digits. But what if your application calls for printed typefaces? Consider the benefits as well as the limitations when choosing between open source vs. self-gathered data sets.
It is a good idea to start by asking specific questions to quantify all the possible bases you must cover with your data set. What is the specific goal you are trying to achieve by using a deep learning system? What will deep learning bring to your project that other systems will not be able to attain? Based on the answers you receive, you need to work out the type(s) of data you will need to match the criteria that these answers present, and therefore solve the problems you are finding solutions for.
I have a data set, what now?
Once you have your data set, the next step must be preparing your data set for deep learning. In the context of deep learning, it is crucial that you carry this out in order for the data to be optimised and suited to its function.
A long task as it may be – taking up most of the time you will spend on your deep learning project – it is vitally important. Consider the time freed up later when your imaging processes are automated.
Data Preparation
Once you have gathered the dataset, it is important to take some perspective to investigate it. Does it cover all the possible variations? You might have an imbalanced image set, which can be fixed by over-sampling the class that is underrepresented, or under-sampling the over-represented class.
All of this is done with a technique called data augmentation, which allows to oversample by using methods like rotation and scaling of the existing images.
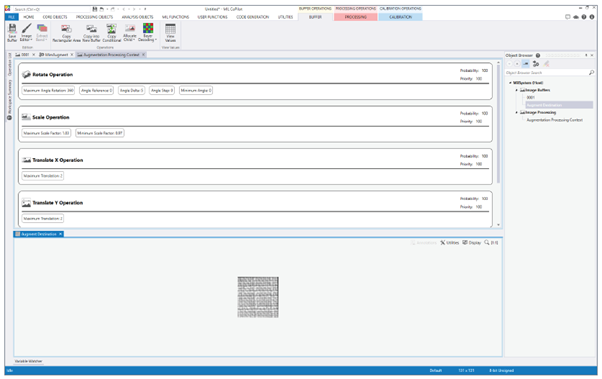
Data augmentation using powerful machine vision deep learning software:
Matrox Imaging Library (MIL) CoPilot
The next step is also to understand whether you are building a model from scratch or taking advantage of an already pretrained model. In the case of building a full model, the number of images needed will be much higher than in the case of using a pretrained model. The latter is a technique called transfer learning and it is very commonly used amongst most machine vision applications.
Transfer Learning
The alternative to training a neural network from scratch, transfer learning is the process of taking a pre-trained network and re-training a few layers of it in order to adapt it to a new task. This can be an effective way to gain momentum quickly on a project as the overall performance of the network is very similar to that of a brand new one trained from scratch, but far less training data is required to get going.
Cutting Edge Deep Learning Solutions from ClearView Imaging
We understand that preparing for a deep learning machine vision project can feel like a mountainous task. At ClearView Imaging, not only do we supply all the components you will need for your machine vision project, but we also have a great team of technical engineers and vision experts with the knowledge and experience to help you with your application. Whatever the question or query, feel free to get in touch via our contact page.
Stay tuned to this series of blogs as we continue to explore deep learning in a variety of machine vision contexts.
Whether you’re an OEM, a system integrator, engineer or even an end user, be sure to check our great range of machine vision products for the best machine vision components on the market.