
Cómo entrenar un sistema de aprendizaje profundo para visión artificial
Como se describe en nuestro último artículo del blog, existen una amplia gama de beneficios atractivos que se pueden obtener al implementar un sistema de visión artificial de aprendizaje profundo en entornos industriales. Cubrimos la definición de aprendizaje profundo, aprendizaje automático e IA, y abordamos los conjuntos de datos y la preparación necesaria para entrenar un sistema de aprendizaje profundo para proyectos de visión artificial.
En esta publicación de blog, profundizaremos en este tema y describiremos las etapas que deberá seguir para entrenar un sistema de aprendizaje profundo para visión artificial.
Entrenamiento de un sistema de aprendizaje profundo con conjuntos de datos
Los conjuntos de datos para soluciones de aprendizaje profundo son tan importantes como la electricidad de la red. Es la "educación" que necesita un modelo para empezar a funcionar como se espera. Para una definición e introducción a los conjuntos de datos, consulte nuestra última publicación del blog.
Sin un conjunto de datos que su modelo procese, no sabrá cómo distinguir entre las variables de las imágenes y, en última instancia, fallará en el uso previsto.
Subconjuntos de datos para visión artificial
Es ideal utilizar tantas imágenes para un conjunto de datos porque deberán asignarse a al menos dos (preferiblemente tres) subconjuntos antes del entrenamiento. El primer subconjunto (el conjunto de "entrenamiento") se utiliza para realizar el entrenamiento real del modelo, lo que implica ajustes en los pesos matemáticos.
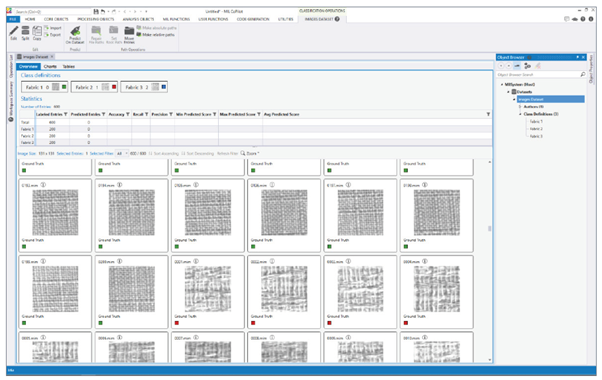
Organización y etiquetado del conjunto de entrenamiento con Matrox Imaging Library (MIL) CoPilot.
El conjunto de "desarrollo" (o "validación") es el segundo subconjunto que necesitará. Este subconjunto se utiliza para supervisar el proceso de entrenamiento rastreando la diferencia entre los resultados de clasificación reales y esperados.
El tercer subconjunto, el conjunto de "prueba", es opcional y se utiliza al final del proceso de entrenamiento del conjunto de datos para evaluar de forma independiente el rendimiento del modelo entrenado; si no se utiliza el conjunto de prueba, el conjunto de desarrollo también asumiría esta función de evaluación del rendimiento.
Construcción de un buen conjunto de datos
Su conjunto de datos debe coincidir estrechamente con las imágenes que espera obtener en su proyecto real.
Cuantas más variables pueda imaginar, mejor. Cuanto mayor sea el número de elementos únicos en su conjunto de datos, mejor. Si puede mantener un entorno coherente (como la iluminación) entre su conjunto de datos y su proyecto en la práctica, más precisas serán las inferencias y la capacidad de toma de decisiones de su IA.
¿Qué tipo de datos necesito?
En el contexto del aprendizaje profundo para la visión artificial, su conjunto de datos consistirá en imágenes de objetos que difieren en función de las posibles variaciones de esos objetos. Como hemos señalado hasta ahora, los sistemas de visión de aprendizaje profundo son los mejores en clasificación, reconocimiento, lectura y detección.
Piense en cómo desea comenzar a automatizar sus procesos; intente comenzar poco a poco, por ejemplo, con la detección básica de la presencia de un objeto, y avance hacia inferencias más matizadas, como la clasificación y la lectura.
El reconocimiento óptico de caracteres (OCR) es una tarea en la que el aprendizaje profundo destaca. Para ello, su conjunto de datos consistiría en muchas variaciones de todos los caracteres posibles que puedan aparecer en la formación de imágenes prácticas.

MNIST es un conjunto de datos de aprendizaje profundo de código abierto muy popular que comprende 70.000 ejemplos de dígitos escritos a mano. Pero, ¿qué pasa si su aplicación requiere tipos de letra impresos? Considere los beneficios y las limitaciones al elegir entre conjuntos de datos de código abierto y auto-recopilados.
Es una buena idea comenzar formulando preguntas específicas para cuantificar todas las bases posibles que debe cubrir con su conjunto de datos. ¿Cuál es el objetivo específico que intenta lograr al utilizar un sistema de aprendizaje profundo? ¿Qué aportará el aprendizaje profundo a su proyecto que otros sistemas no podrán conseguir? En función de las respuestas que reciba, deberá determinar el tipo o los tipos de datos que necesitará para que coincidan con los criterios que presentan estas respuestas y, por lo tanto, resolver los problemas para los que busca soluciones.
Tengo un conjunto de datos, ¿y ahora qué?
Una vez que tenga su conjunto de datos, el siguiente paso debe ser prepararlo para el aprendizaje profundo. En el contexto del aprendizaje profundo, es crucial que lo lleve a cabo para que los datos se optimicen y se adapten a su función.
Por muy larga que sea la tarea, que ocupará la mayor parte del tiempo que dedicará a su proyecto de aprendizaje profundo, es de vital importancia. Considere el tiempo que se ahorrará más adelante cuando sus procesos de imagen estén automatizados.
Preparación de datos
Una vez que haya recopilado el conjunto de datos, es importante tomar cierta perspectiva para investigarlo. ¿Cubre todas las posibles variaciones? Es posible que tenga un conjunto de imágenes desequilibrado, que se puede corregir mediante el sobremuestreo de la clase subrepresentada o el submuestreo de la clase sobrerrepresentada.
Todo esto se hace con una técnica llamada aumento de datos, que permite el sobremuestreo utilizando métodos como la rotación y el escalado de las imágenes existentes.
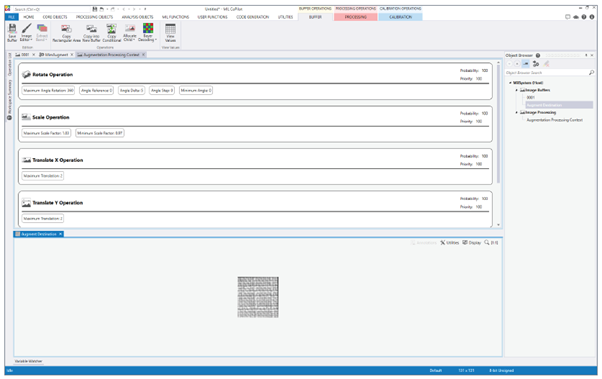
Aumento de datos utilizando un potente software de aprendizaje profundo para visión artificial:
Matrox Imaging Library (MIL) CoPilot
El siguiente paso también es comprender si está construyendo un modelo desde cero o aprovechando un modelo ya entrenado. En el caso de construir un modelo completo, el número de imágenes necesarias será mucho mayor que en el caso de utilizar un modelo preentrenado. Esta última es una técnica llamada aprendizaje por transferencia y se utiliza muy comúnmente en la mayoría de las aplicaciones de visión artificial.
Aprendizaje por transferencia
La alternativa a entrenar una red neuronal desde cero, el aprendizaje por transferencia es el proceso de tomar una red pre-entrenada y reentrenar algunas de sus capas para adaptarla a una nueva tarea. Esta puede ser una forma efectiva de avanzar rápidamente en un proyecto, ya que el rendimiento general de la red es muy similar al de una nueva entrenada desde cero, pero se requieren muchos menos datos de entrenamiento para empezar.
Soluciones de vanguardia de aprendizaje profundo de ClearView Imaging
Entendemos que prepararse para un proyecto de visión artificial de aprendizaje profundo puede parecer una tarea abrumadora. En ClearView Imaging, no solo suministramos todos los componentes que necesitará para su proyecto de visión artificial, sino que también contamos con un gran equipo de ingenieros técnicos y expertos en visión con el conocimiento y la experiencia para ayudarlo con su aplicación. Cualquier pregunta o consulta, no dude en ponerse en contacto a través de nuestra página de contacto.
Permanezca atento a esta serie de blogs mientras continuamos explorando el aprendizaje profundo en una variedad de contextos de visión artificial.
Tanto si es un OEM, un integrador de sistemas, un ingeniero o incluso un usuario final, asegúrese de consultar nuestra gran variedad de productos de visión artificial para encontrar los mejores componentes de visión artificial del mercado.